编者按
在 2023 年 11 月,OpenAI 创始人之一 Altman 提到,ChatGPT 每周都有一亿的活跃用户,这也是一个令人惊讶的数字。有报道指出,92% 的财富 500 强公司都在使用 OpenAI 的平台。还有一些奇特的统计数据,例如有 32% 的美国人使用 ChatGPT 来规划旅行路线。尽管 ChatGPT 刚刚发布,仅有一年的时间,但它的使用速度和频率在这一年内迅速增加。
OpenAI 的 ChatGPT 模型目前被广泛应用。在国内也涌现了许多类似的大语言模型,技术发展迅速。截至今年三月份,ChatGPT月付费用户已达到 1.8 亿,这个数字惊人。OpenAI 公司的 Plus 账户每月收取 20 美元的费用,这个付费用户基数非常庞大。
然而在使用 ChatGPT 的过程中,很多人并不了解它的工作原理,使用时存在一些盲目性。有一个统计数据提到,只有 3% 的人真正领会到 ChatGPT 的使用技巧,以便更好地获取所需的答案。因此,我们需要简要了解一下 ChatGPT 的工作原理,以避免由于不了解工作原理而导致的潜在问题。
为此我们特别邀请到我校MBA商业信息系统王刚教授做客Kepha MBA“商道论坛”直播间与大家分享了一些关于 ChatGPT 的基本概念以及应用和操作的技巧。敬请师友们关注,并转发个有需要的人士。
01. ChatGPT 的工作原理
很多人并不了解ChatGPT的工作原理,使用时存在一些盲目性。例如,有些人将 ChatGPT 视为个人助手,期望它能像科幻电影中的机器人助手一样完美地回答问题。然而,ChatGPT 远远没有达到星球大战中所展示的 2 to d to 机器人的智能程度。因此,了解 ChatGPT 的基本工作原理非常必要。
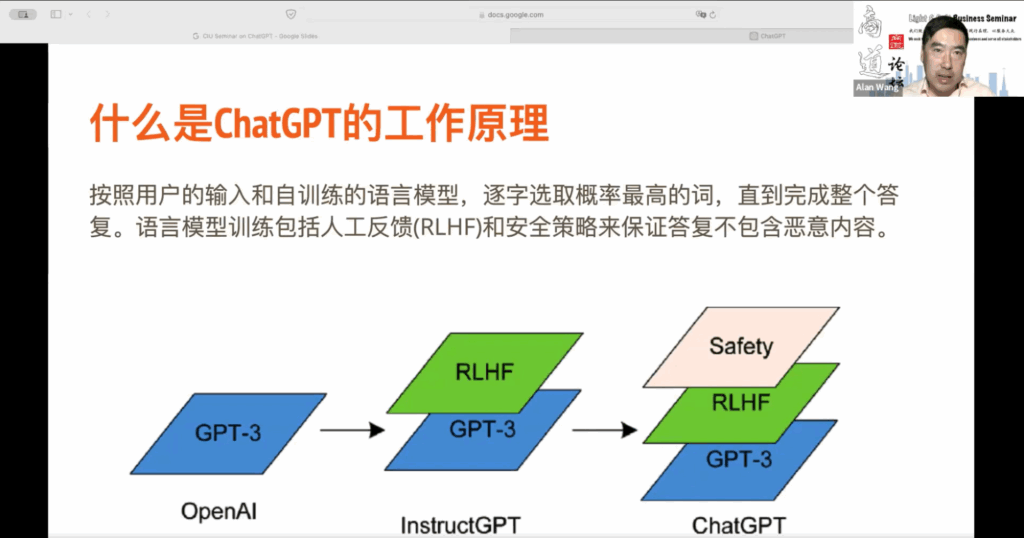
首先,让我们简单了解一下 ChatGPT 的工作原理。ChatGPT 是一个自训练的语言模型,通过大量已发表的文章,包括维基百科和网络上其他高质量的文章进行训练。你可以把这个语言模型想象成一个小孩子,他没有见过任何人,没有听过任何人说话,也没有见过任何场景。然而,通过大量数据的不断训练,他可以自己生成句子,理解词语和句子之间的关联,就像我们中国有句谚语:“书读千遍,其义自现”。对于 ChatGPT 来说,这就是它的工作原理。它在训练过程中找到字与字之间、词与词之间的关联,并根据用户的输入和上下文,猜测每个字出现的顺序。当用户输入提示词后,它会基于这些提示词来生成答案的每个字,按照概率来确定下一个字,直到完成整个答案。因此,在提供回应时,你会发现 ChatGPT 逐字逐句生成答案。通过这种自训练的语言模型,我们可以更好地理解它的工作原理。
ChatGPT 3,它是一个完全机器训练的模型,无需人的参与。然而,我们会发现,如果仅仅依赖机器训练,会出现一些问题。首先,数据本身可能存在偏见。例如,如果数据中不断重复某种观点,比如“人性本恶”或“人性本善”,那么在 ChatGPT 3 的训练过程中,这些偏见会被保留下来,这就是一个问题。
另一个问题是,人们在网络上的讨论中可能会出现许多危险的言论,这些言论不应该不加判断地传播给任何人。为了确保机器训练的模型能够过滤掉不良信息,需要利用个人的反馈。这就是 Reinforce Learning with Human Feedback(RLHF),即利用人的反馈来加强学习的过程。这项工作需要大量的人力资源,尽管存在一些成本压力和争议,但其目的是确保答案的准确性和干净性。
所以,我们有了 Instruct GPT 这个模型,它基于 GPT 3 的自训练语言模型,通过人类的反馈来指导模型的学习。最后,ChatGPT 还有一套安全政策,以确保在处理敏感问题时能够给出恰当的回答,或者拒绝回答。
在使用 ChatGPT 时,我们可能会遇到一些偏见的问题。首先,自训练语言模型可能会在模型中固化现有数据中的偏见。其次,人类提供的反馈也可能受到个人偏见的影响。最后,安全标准可能因文化和法律的差异而有所不同。因此,在使用 ChatGPT 时,我们可能会得到意料之外的回答,因为有许多因素影响着它的回应。
02. 影响提示词质量的因素
目前,我们无法完全理解 ChatGPT 为何会给出某种回应,因为大型语言模型仍然像黑箱一样。然而,我们可以通过提示词的工程来影响 ChatGPT 的回应,从而达到我们期望的答案。因此,今天我们要讨论的重点是如何通过提示词来影响 ChatGPT 的思考过程,以获得我们所期望的答案。
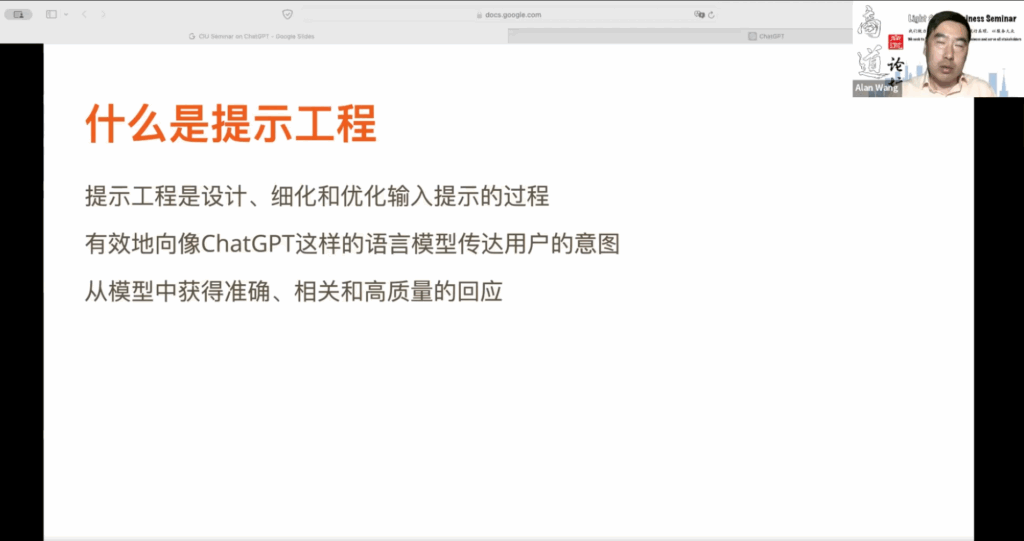
我想谈一谈“提示词工程”,这也称为“提示工程”。你可能注意到,在网上有很多在线课程教你如何编写提示词,以获得你希望的 ChatGPT 回应。提示词工程旨在设计、细化和优化 ChatGPT 交互过程中我们给予的指令。由于 ChatGPT 具备广泛的知识背景,它通过训练从互联网上获取的大量数据而成,因此在设计提示词时,必须清楚表达意图,明确所希望的知识或回复所属领域。
我们需要在提示词中清晰具体地表达意图,才能从模型中获取准确相关、高质量的回复。这就是所谓的提示工程。科学研究表明,提示词的质量与获得的 ChatGPT 回复的质量呈正相关关系。有些研究甚至发现,通过提高提示词质量,可以使回复质量提高多达50%甚至更多。

那么影响提示词质量的因素是什么呢?首先,必须明确表达意图。在与 ChatGPT 进行交流之前,我们必须清楚我给 ChatGPT 的提示词,以及我或我试图从 ChatGPT 获取的信息的任务类型。例如,我们是想获得一些特定信息,比如法国首都的位置,或者美国国旗的外观。如果我们的意图是生成新内容,我们需要告诉它,例如,我们希望做一份旅游规划,包括时间、预算和其他要求。此外,意图必须表达清晰,无论是生成新内容还是解决问题。
其次,必须针对所用的大型语言模型的特点进行设计。每个模型都有自己的特点。尽管今天的讲座重点是 ChatGPT,但提示词工程的原则适用于所有大型语言模型。然而,由于不同公司在第二步和第三步的处理方式不同,每个模型都有其独特之处。因此,我们必须了解所使用模型的特点,例如国内的一些模型,如文心一言,在提示词上可能有所不同。
第三,如果涉及特定领域的问题,我们必须提供该领域的背景信息,以帮助模型更好地找到相关的模型参数,并利用模型的关注点来提供更相关的回复。
另外需要进行一个判断,以确定你的提示词是否会产生误解或模糊的提问。因为某些词语可能具有双关的意味,在不同的领域可能有不同的含义,所以你必须告诉 ChatGPT 你所问的问题是属于哪个领域?或者是在什么环境下提出的?具备了这些背景信息,可以避免误解的发生。
此外,你还应对回应提出一些要求。在与 ChatGPT 进行交流时,大多数人通常将其视为语音助手,只是简单地表达想要什么。但我们很少对模型提出明确的要求。因此,我建议你明确告诉 ChatGPT 你对回应的要求,比如要满足哪些条件。这是非常必要的,因为 ChatGPT 往往会根据自己的理解给出回应,这可能与你真正想要的回应不同。如果没有明确的要求,你可能会花费更多的时间与 ChatGPT 进行交流,以达到你想要的回应。
03. 低质量的提示词带来的问题
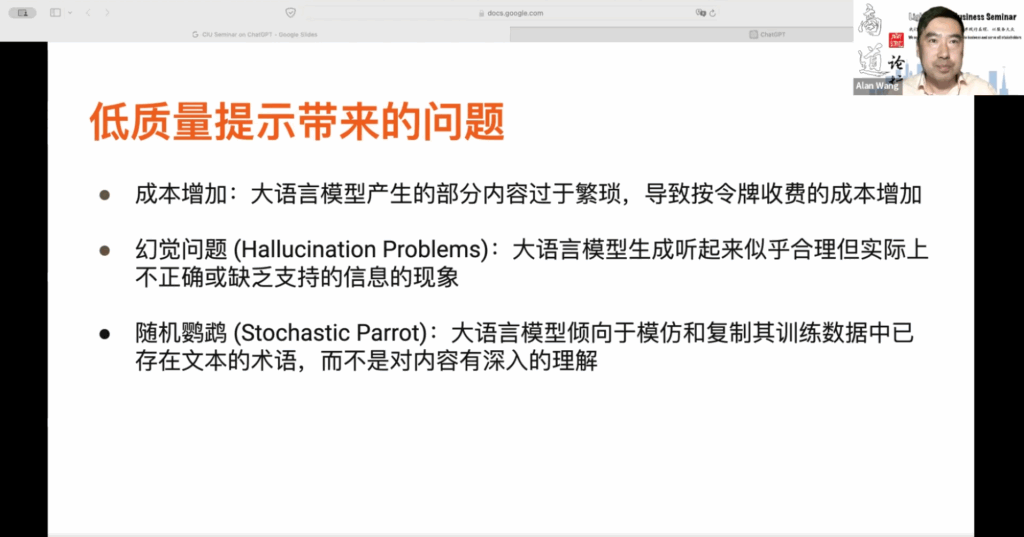
低质量的提示词会带来一系列问题。正如我们刚刚提到的,成本会增加,因为低质量的提示词需要进行多轮交流,才能得到期望的回应。许多大型语言模型的使用与其 API 相关。许多用户并非直接通过在线平台与 ChatGPT 进行交流,而是通过内置的 ChatGPT 聊天模块使用 API 进行交流。API 的成本会随着大型语言模型处理的字数而增加。有时你会发现,如果提示词的质量很低,大型语言模型会提供大量繁琐的内容和解释,这些解释可能并不必要。这可能会导致按 API 令牌收费,进而导致成本大量增加。
除了成本问题,回应的质量也是一个问题。你可能听说过一些问题,比如所谓的“幻觉问题”。这指的是大型语言模型生成的回应听起来很合理,但实际上不正确或缺乏支持信息。我曾在去年 ChatGPT 推出时进行了一次有趣的实验。当时我需要在纽约转机,纽约有三个机场:纽瓦克、拉瓜迪亚和新泽西机场。我需要从拉瓜迪亚机场到新泽西机场转机,并且需要在当地过夜。因此,我询问了 ChatGPT 是否可以为我找到一家旅馆,该旅馆提供机场巴士服务,可以到达拉瓜迪亚机场和新泽西的利伯蒂机场。ChatGPT 迅速给出了五家旅馆的网址,并明确告诉我,这些旅馆提供机场巴士服务到这两个机场。然而,我进入这五家旅馆的网站查看后,发现没有一家旅馆符合我的要求。这就是所谓的幻觉问题。
ChatGPT有时为了迎合你的需求,会强迫自己给出一个答案,这就是幻觉问题的产生。那么现在,这个问题是否仍然存在呢?答案是肯定的。最近有一则新闻报道,在加拿大,一名律师在起草法庭文件时引用了一些案例。他使用 ChatGPT 作为案例检索工具,搜索相关案例,但最终发现引用的案例实际上并不存在。这也是幻觉问题的产生之一。因此,大家务必要警惕,在寻找信息、使用 ChatGPT 进行信息检索时,幻觉问题可能存在。ChatGPT 给出的答案必须经过确认,确保信息的准确性。
04. ChatGPT不能完全理解基本常识
另外一个问题是所谓的“随机鹦鹉问题”。
大型语言模型倾向于模仿和复制其训练数据中已有的文本术语,而不是深入理解内容。有时候我们会误以为大型语言模型完全真实,并且具有相应的知识。实际上,大型语言模型并没有这些知识,它只是知道词与词之间的相对关系。因此,它的表现与我们所谓的常识或知识存在本质区别。很多时候,它的回应只是根据其训练数据中存在的内容给出,如果训练数据中的信息是错误的,那么你就不能期望它有对内容的深入理解,以此来创造新的内容。
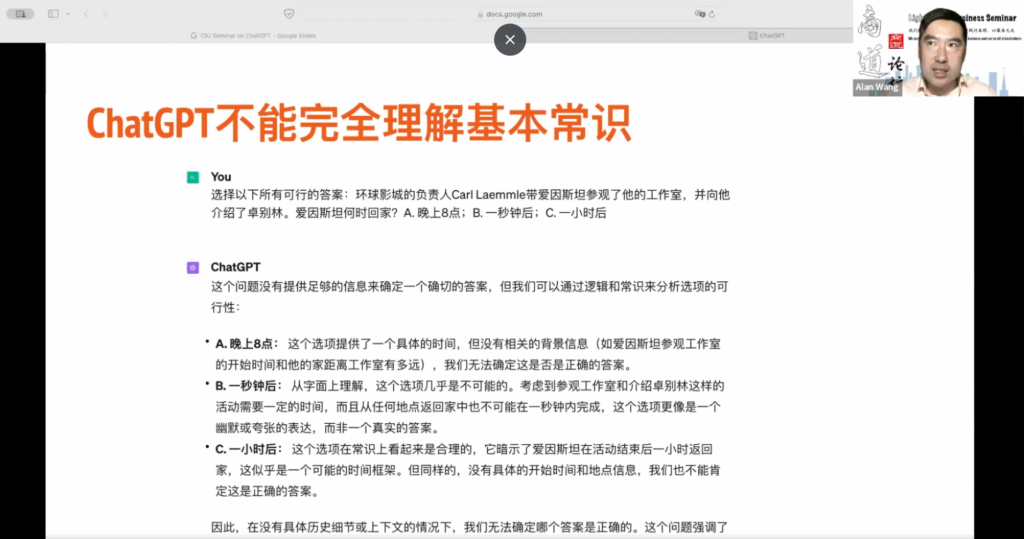
举个例子,我们不能将 ChatGPT 或其他大型语言模型等同于人类。你不能期望它像《星球大战》中的机器人那样直接与你对话,并理解你的情感或回答一些基本问题。最近,我用最新的 ChatGPT 4 模型做了一个实验,从一篇文章中摘录了一个例子。背景是环球影城的负责人 Carl 带着爱因斯坦参观了他的工作室,并向他介绍了卓别林。然后提出了这样一个问题:爱因斯坦几点能到家?选项是晚上 8 点、一秒钟以后和一小时以后。对 ChatGPT 来说,这是一个混淆的问题,因为爱因斯坦和卓别林都是非常特殊的人,模型存储了大量关于他们的信息,这可能会干扰 ChatGPT。
另一个问题是我们没有提供具体的时间,但从常识上来说,我们认为晚上 8 点和一小时以后可能是正确的。因为我们不知道起始时间,所以我们认为一秒钟以后肯定是错误的。对于 ChatGPT 来说,它无法确定晚上 8 点是正确答案,因为它缺乏这种常识。所以我们可以看到,尽管 ChatGPT 根据逻辑和常识来分析选项的可能性,但它并不能等同于人类,它只能基于现有的模型给出最佳答案,但不一定包含所有所需的常识。
05. 提示工程
5.1 提示工程基本原则
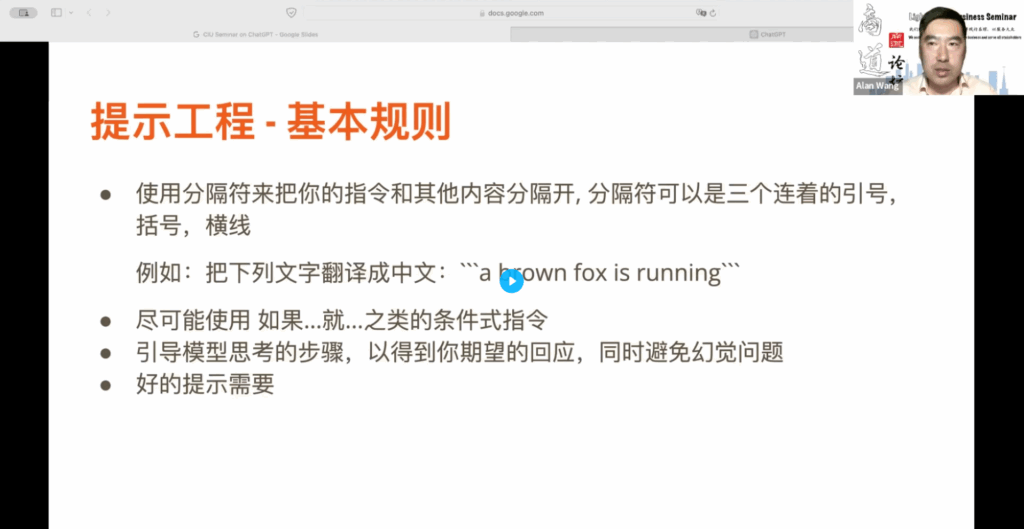
我们来探讨一下提示词工程,它如何影响 ChatGPT 对我们的回应?也许你已经熟知一些提示词的技巧,但我希望大家学习后能够应用到与 ChatGPT 的交流中。首先,你要学会使用分隔符将指令和其他内容分隔开。分隔符可以是三个连续的引号、括号或横线。为什么要使用三个连续的符号?因为很少有文本内容中会出现三个连续的符号,所以使用这种方式可以将指令与内容区分开来。
在如图所示的这个例子里面:把下列文字翻译成中文,用一个冒号,然后在内容两边我用了三个单引号把它括起来。
对于 ChatGPT 来说,它就可以清楚地区分出指令和提供的内容。在提示工程中,尽可能使用:“如果”“就”这样的条件式的指令。对于 ChatGPT 的模型训练来说,这样的逻辑关系很容易记忆,因此给出正确回应的概率会很高。另外,你要引导模型思考的步骤,以获得你期望的回应。这样做的好处是可以避免刚才所提到的幻觉问题。
在我们与 ChatGPT 的交流中,我们经常假设它是一个万能的机器人,就像《星球大战》中的全能机器人一样,可以自行思考。但实际上,ChatGPT 并不能完全理解你想要它思考的步骤。因此,在使用 ChatGPT 时,我们必须主动指导它,而不是被动地等待回应。这就需要我们清楚地知道我们想要什么。
然后我们才可以告诉模型,我们想要的回应它的条件是什么?它的限制是什么?它的思考过程是什么?只有这样,你的模型才不会受到模糊的提示词的影响。因为很多时候,它会给出虚假信息,但在表达时却非常自信,会让你误以为它给出的是正确答案,这就是幻觉问题。我们还要清楚表达在提示中,告诉 ChatGPT 你到底想要什么,这与上一步非常接近。一方面,你告诉它思考步骤,另一方面,你告诉它你想要的回应,你的规定是什么?你的条件是什么?这是一些基本规则,希望大家能够记住。
5.2 提示工程技巧
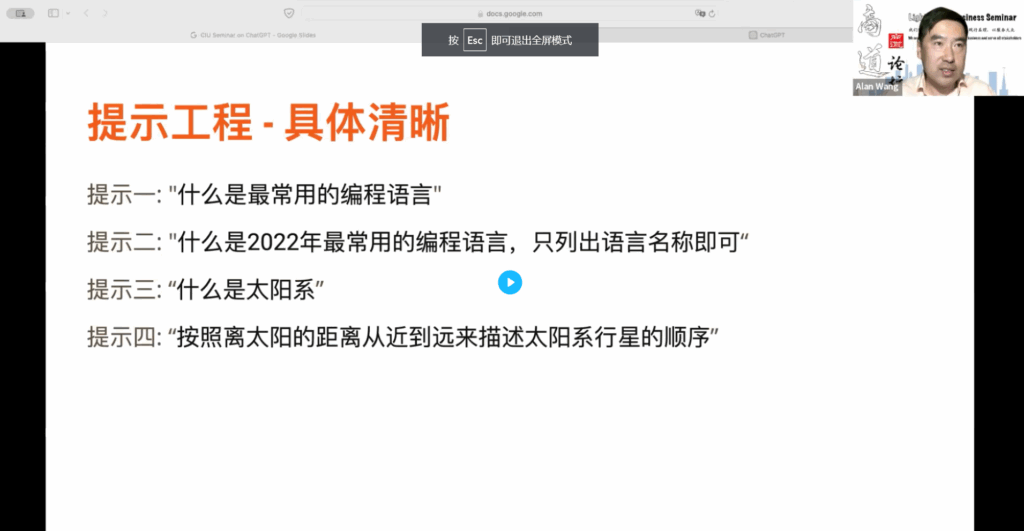
接下来,让我们看一些具体的提示工程技巧。首先,在所有的研究中都强调了一个要求,那就是要具体清晰。在你的提示词中,提供尽可能多的背景信息。例如,我们看第一个提示词:“什么是最常用的编程语言?”这个提示词中包含许多模糊概念,因为“最常用”是一个时间概念。ChatGPT 的训练数据永远落后于最新数据,所以它无法给出当前年份的最常用编程语言。因此,你必须了解 ChatGPT 的局限性。
在提示词中,我们应该回答所谓的5个W 1个 H 的问题。首先是 5 个 W,即:时间、地点、人物、什么、为什么?回答了这 5 个问题之后,你会发现你的答案会变得非常清晰明了。比如,提示二:比提示一要具体清晰得多。比如,你问的是 2022年最常用的编程语言,你应该知道 ChatGPT 它总是想要给你一个解释。但实际上很多时候你并不需要这些解释,你只需要语言的名称就可以了。
在这里我提到了我的需要,我的回应的要求是什么?你只需要给我语言的名称就可以了,你不需要为每种语言解释它们的用途,这样可以节省很多时间成本。因为 ChatGPT 它是逐词生成的。如果它给你一个很长的回复,会花费很多时间来提供一个非常繁琐的回答。有时候我们并不需要繁琐的回答,你必须要告诉 ChatGPT,你期望的回应的格式是什么?同样,我们来看提示三:什么是太阳系?这个问题就非常广泛,是关于太阳系的大小吗?还是太阳系的形成?还是太阳系的其他方面?对于 ChatGPT 来说,它一定会给你一个答案,但这个答案可能会非常繁琐。
提示四:你可以问一个具体的问题,比如,按照太阳离太阳的距离远近,我们来描述一下太阳系行星的顺序。所以你要清楚你想要的是什么,你会提出一个非常具体和清晰的提示。很多时候,这也是在使用大语言模型时需要避免的一个误区,就是一旦我们真的把它当做助手,我们就不愿意再去思考。实际上,如果我们能够与大语言模型建立共生关系,那么现在很多人讨论的可能被生成式人工智能取代的问题,我认为不必担心。因为你永远是一个主动地引导模型去思考的人,而不是被动地希望模型替你完成思考的人。
所谓具体清晰,其实它虽然是一个提示词的要求,但它反映的是我们内心必须要有一个思考。我们必须要知道我们想要的信息是什么?我们想解决的问题是什么?我们问题的背景是什么?我们需要提供这些具体的信息。另外,在回应方面的要求也应该具体清晰,我们都有一个具体清晰的定义,具体清晰原则这一要求,我们也应该做到这一点。
5.3 提供背景信息

第二个提示与第一个提示相似,但更接近。你需要提供背景信息。所谓提供背景信息是指,首先告诉 ChatGPT 它所扮演的角色是什么,通过这个角色扮演,帮助 ChatGPT 更好地使用相应的语言。例如,提示一要求写一篇关于介绍新冠疫苗的文章。这个提示词很模糊,因为我不知道应该从什么角度来写这篇文章。我是以记者的身份写这篇文章?还是以学生的身份?还是以教授的身份?提示二更为明确,它指出我是一名医生,或者你可以告诉 ChatGPT,你是一名医生。
写一篇关于新冠疫苗的文章,用于培训其他医疗专业人士。因此,目的也更为明确。你的角色和回应的目的也就更加清晰。这样你会发现这篇文章更符合你的需要。这是一个背景信息。另一个背景信息是,你可以提供方法:例如,当你想让 ChatGPT 给你一个特定回应时,你可以先给它一个例子,让这个例子帮助它更好地理解问题。举例来说,我们看看提示三和提示四。提示三问:导流和对流的区别是什么?这是一个非常大的物理学概念的对比。如果你将提示三放入 ChatGPT 中,你会发现得到的答案非常科学、非常专业,里面会包含许多物理学的专业术语。因为你提供的背景信息有限,ChatGPT 会自动找到与物理学专业相关的内容。
如果我们期望得到的答案更加通俗易懂、更具启发性,我们可以使用提示:我们可以说:“用平底锅和烧水来做例子,来解释导流和对流的区别”。这时 ChatGPT 就会意识到平底锅和烧水这两个词是提示,表明应该用通俗易懂的语言来解释区别。因此,你会发现两个提示所得到的回答截然不同。另一种提供背景信息的方式是,提供一个例子。例如,对于翻译,你可以先给出一个中英文对照的例句,然后再给出一个英文句子,让 ChatGPT 翻译成中文。这样通过一个例子来提供背景信息,告诉 ChatGPT 你期望的翻译是什么样的,或者翻译的质量应该如例子所示。
另外,你要给出对于你所需要问的问题的一个区别。比如说,如果你想得到一个事实类的信息,比如搜索信息,就像我们刚才提到的法国的首都是什么,你可以直接问法国的首都是什么。因为你知道这个事实类的问题是唯一的,它会很快给出答案,并且你也知道这种问题不太会产生模糊性,所以可以直截了当地提问。因为这是一个事实类的问题。
5.4 区别问题的实质
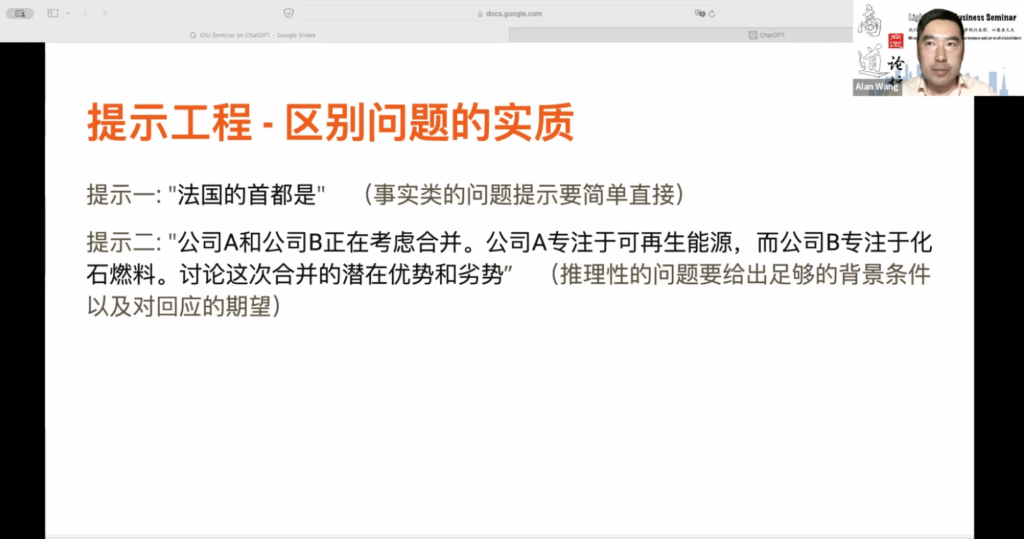
第二个问题是,如果你的问题是一个推理性的问题,但并不期望一个固定的答案,这个时候你需要给出足够的背景条件,并明确你对回应的期望,才能得到答案。如果我们只是让 ChatGPT 自己进行推理,你要知道因为它的训练数据的多样性,有时会包含错误信息。所以你不希望模型被错误信息误导,这就是为什么我们要提供这些背景信息,以帮助模型找到正确的参数,给出你所期望的回应。
对于回应的要求也有一些技巧,比如你可以限定回应的格式。首先,我们看到一个提示是写一篇关于新冠疫苗的文章,字数为 500 字。尽管 500 字已经是一个限定,但这个限定还是相对较少的。看第二个提示,它更明确,要求撰写一篇关于新冠疫苗的论文,字数为 500 字,包括引言、背景、好处、潜在问题和结论等几个部分。这样,你就提前确定了文章的结构,使得 ChatGPT 更容易填写这几个部分,更符合你的要求。
5.5 限定回答的格式

提示三是简要解释水循环,但这个“简要”怎么定义呢?简要意味着清晰明了,但对于 ChatGPT 来说,这个要求略显模糊。这时,我们需要设定一个回答的格式,比如要求提供水循环的详细解释,包括各个阶段和过程,这样 ChatGPT 就知道从哪个方面给出回应。因此,限定回答的格式至关重要。在撰写提示词时,给出许多限制条件非常关键。提示一并没有提供这些限制条件。
5.6 给出限制条件
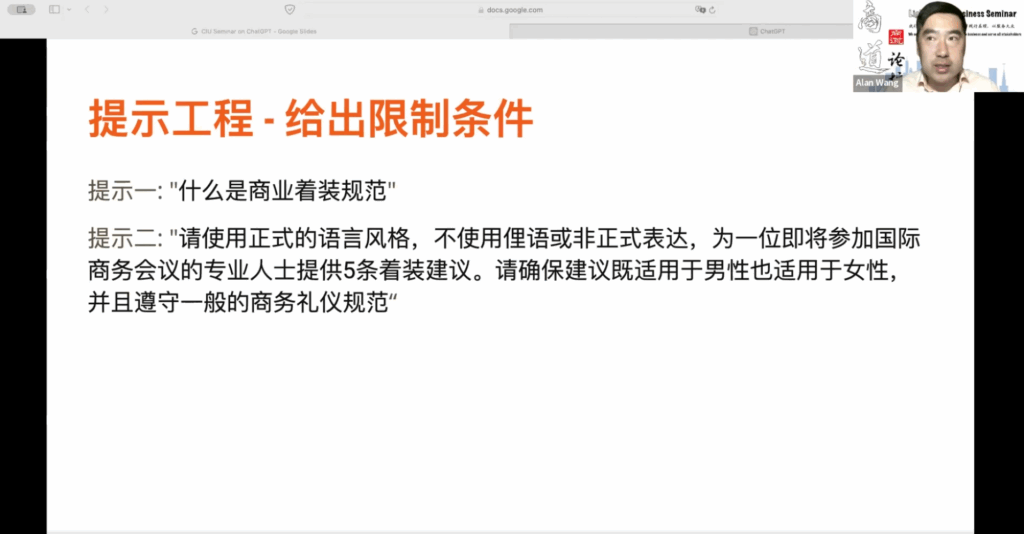
什么是商业招待装规范?我们只是想要一个通用的回答,但如果你能提供更具体的商业仪式信息,那么得到的着装规范会更符合你的需求。例如,商业招待装规范可以用于商务会议介绍或商务会议邀请。你希望这些着装规范使用正式的语言风格,而不是俚语或非正式语言。因此,你可以明确要求使用正式的语言风格,避免俚语或非正式表达。然后,为即将参加国际商务会议的专业人士提供 5 条着装建议。这里,“国际”是一个限制条件。确保建议适用于男性和女性,并符合一般的商务礼仪规范
5.7 给出例子
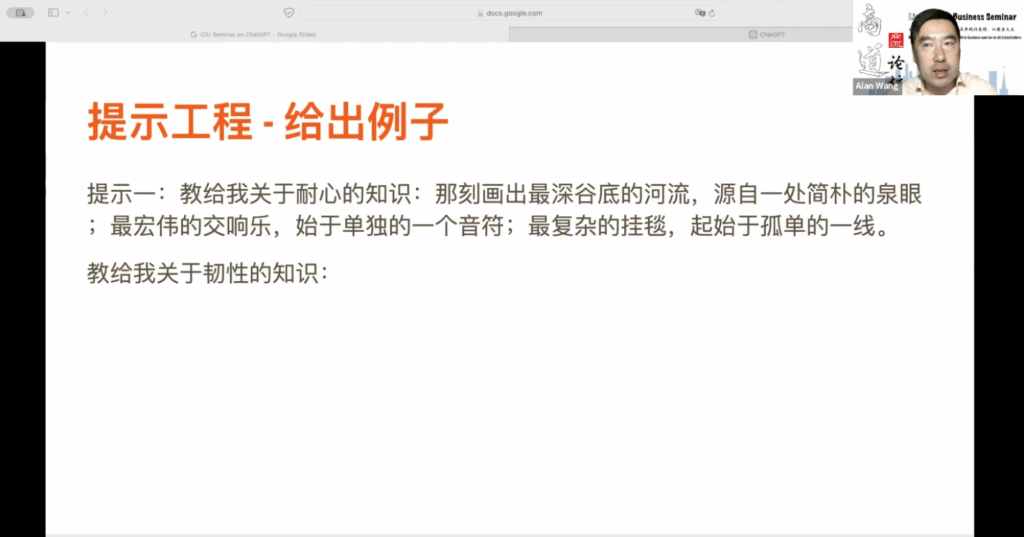
如果只使用提示一,我们只会得到一般的商务礼仪规范,而不能得到真正想要的答案。因此,在给出限制条件时也非常重要。刚刚提到的例子技巧有时非常关键,特别是在 ChatGPT 给出所期望答案时。例如,提示要求教授关于耐心的知识,随后用一首诗表达耐心的重要性。这种诗情画意的解释可以有效教导关于耐心的知识。如果你把这个提示输入到 ChatGPT 中,你可能会得到一首诗作为回答。
他用诗歌来讲述韧性为何如此重要。你可以尝试这样做,给出一个诗歌的例子,它会给出相应的回答。因此,有时候提示词的技巧对于获得期望的回答非常有帮助。你会发现,只要有现成的例子,这种提示词的技巧就非常有效。
5.8 根据回答修改提示

还有一个常用的提示词技巧叫做“Multi turn prompt engineering”,即多回合的提示工程。有时你可能不清楚如何构建提示词,可以先给出一个提示,然后根据回答再修改后续问题。例如,当你问关于运动对健康的好处时,可能会得到很多不同的答案,包括心血管方面的。你可以追加问题,询问有规律的运动对心血管健康的好处,或者是否有精神健康方面的好处。这就是多回合的提示工程。
5.9 让ChatGPT帮你
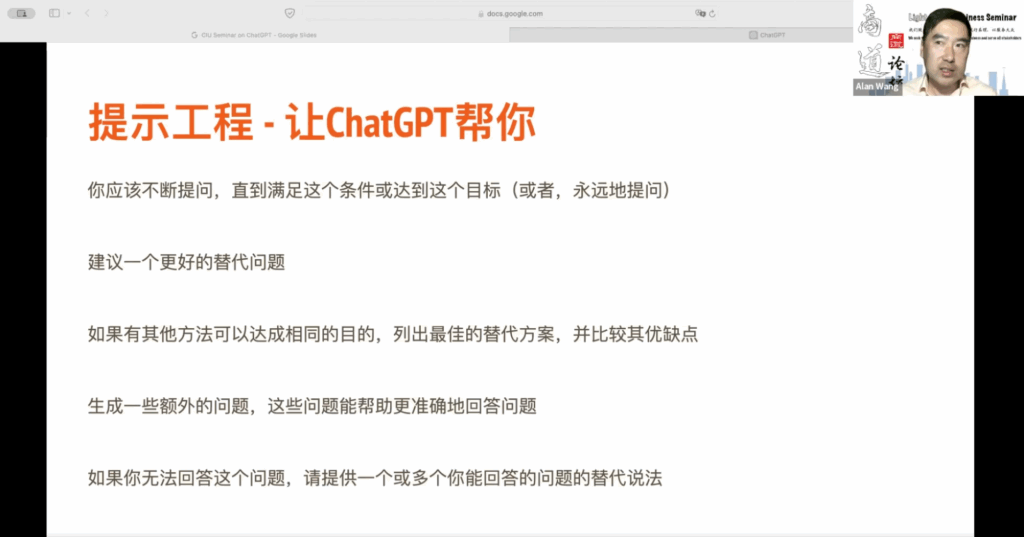
有时候你确实不知道该如何构建提示词工程,尤其是当你刚开始使用 ChatGPT 时,可能你意识到提示词工程的重要性,但并不确定具体方法。这时,ChatGPT 可以成为你的老师,你可以询问它:“我该如何编写提示词?”刚刚提到的 Multi-turn prompt engineering 允许你不断提问,直到得到满意的回答。
此外,当你提出一个问题但不确定提示词是否合适时,你可以询问 ChatGPT 给你一个建议,一个更好的替代问题。这是我常用的技巧,尤其是在我不熟悉的领域。你可以让 ChatGPT 提供一个更精准的问题或更恰当的提示词,然后继续提问。
假设你在撰写商业战略文档,希望 ChatGPT 帮助你制定战略。你提供了一个思考过程,但不确定它是否最佳。这时,你可以追加一个问题,询问 ChatGPT 是否有更好的思考方式。你可以提出这样的提示词:“请按照以下步骤思考商业战略。”
在给出背景信息后,描述商业战略思考过程,考虑竞争力和成本风险等因素。最后,陈述如果有其他方法可以得到更好的商业战略,列出最佳替代方案,并比较它们的优缺点。
在完成基本指令的同时,ChatGPT 可以自行思考,寻找更好的商业战略思考过程。有时你不确定如何提问或书写提示词,你可以让 ChatGPT 生成额外的问题,以更准确地回答之前的问题。最后,有时你可能会发现 ChatGPT 无法回答问题,可能是因为你的提问角度被误解,或者被误认为是在寻求非法或不道德的信息。
假设此时 ChatGPT 对你有误解,你可以请求其提供一个或多个能够回答问题的替代说法。有时候,ChatGPT 可能会由于其安全政策而无法回答你的问题,特别是涉及种族问题时。在这种情况下,你可以询问它如何更准确地提问以获得答案。
5.10 事实核查
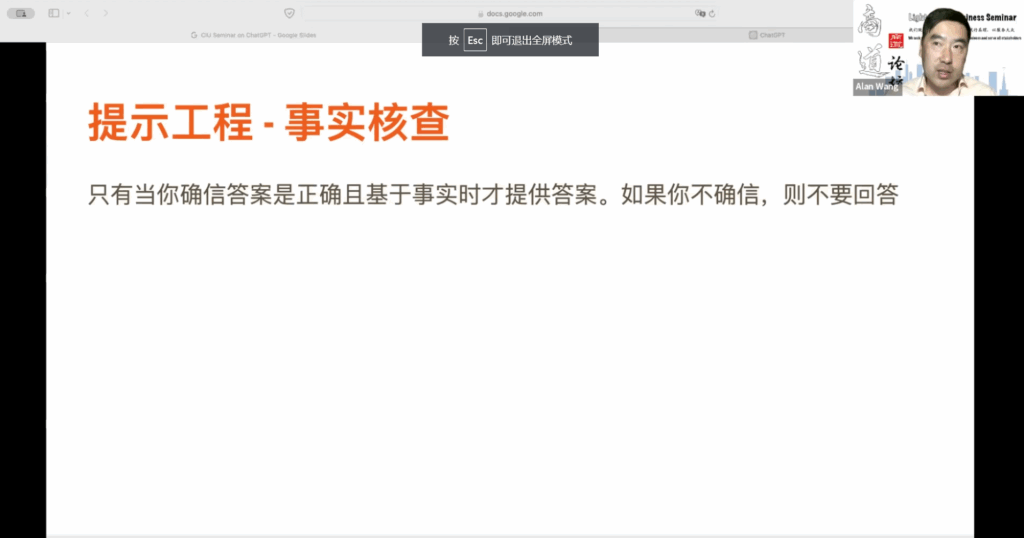
另外,我们提到了事实核查问题,这在进行事实核查时非常重要,特别是当你期望基于事实回答问题时。在提问这类问题时,一定要附加一句话:“只有当你确信答案是正确并基于事实时才提供答案。如果你不确定,请不要回答。”这是因为在训练过程中,ChatGPT 倾向于试图迎合用户,有时即使没有正确答案,也会提供答案,因为用户期望如此。
如果你添加了限定条件,ChatGPT 会告知没有正确答案,或者你可以要求提供信息来源,这样你就能判断答案的准确性了。
有许多不同的提示词技巧,可能会令人头疼。当然,如果你想要 ChatGPT 成为你的工具而不是取代你的工作,你必须了解其工作方式,并主动控制其思考过程。
5.11 提示词并非越复杂越好
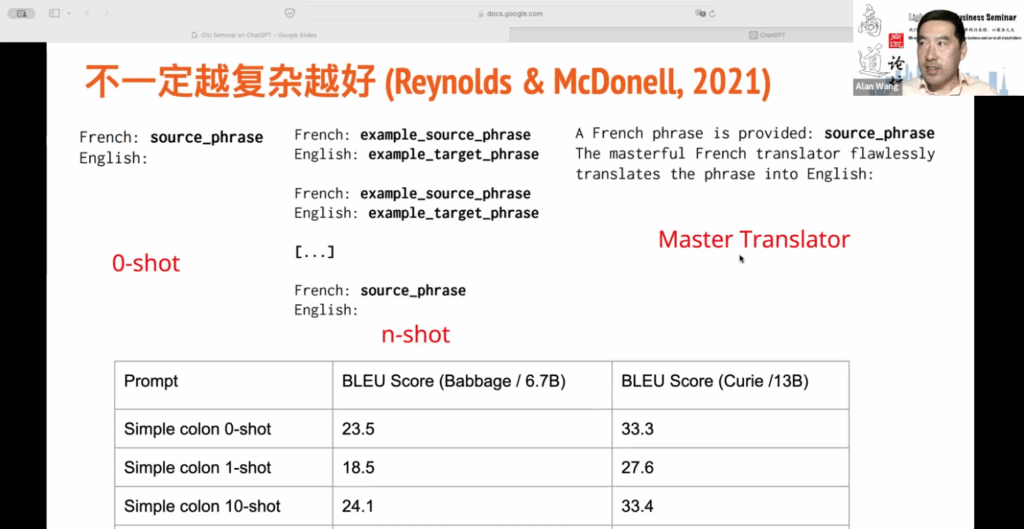
是否提示词越复杂越好?并非如此。有时候,存储一些好的提示词并根据不同类型的问题使用它们更有效。在2021年,Reynolds 和 McDonald 发表了一篇文章,探讨了这个问题。他们的实验发现,并非提示词越复杂越好,很小的变化也会对结果产生重大影响。尽管这个实验是关于机器翻译的,但我们可以在后续的提示词中发现更多技巧,以获得我们想要的答案。
让我来解释一下一个实验,它是关于机器翻译的,具体来说是将法语翻译成英语。实验采用了三种不同的格式来设置提示词。
首先是所谓的 “Zero shot”。这意味着直接提问,不提供任何背景信息。只需输入一个法语词,然后加上英语冒号,将提示词输入到 ChatGPT 中。ChatGPT 将显示相应的英语翻译。这种方式没有背景信息的铺垫。
第二种格式是 “n shot”。在提问之前,会提供很多法语和英语之间的翻译例子。你可以提供一个或多个例子,例如提供一个例子是 “one shot”,提供两个是 “two shot”,以此类推。
第三种格式是 “Master Translator”。它告诉 ChatGPT 一个角色定位,让它扮演翻译大师的角色,完美地将法语翻译成英语。这种方式要求 ChatGPT 完美地完成翻译任务。
实际上,这些任务的本质相同,但提示词不同会导致不同的结果。实验使用了一种叫做 BLEU 分数的指标来衡量翻译质量,以评估其与人类翻译的接近程度。分数越高越好。你会发现 “Zero shot” 没有提供任何背景信息的情况下,使用这种格式的得分达到了 R3.5。但实际上,“Zero shot” 提示词与我们通常使用的 “Zero shot” 提示词并不相同。举个例子,当 OpenAI 最初进行实验时,他们使用了简单的提示词,比如将法语翻译成英语,然后将法语词放在上面,结果并不理想。
这篇文章采用了一种不同的形式,即使是在 “Zero shot” 的情况下,将没有提供背景信息的提示词改为了冒号形式的提示词。这比仅仅将法语翻译成英语的提示词要好。我没有列出数据,但之前的得分可能在十几分,现在经过简单的 “Zero” 格式转变后,得分已经有了很大的提升。然而,如果在提问翻译问题之前提供了一个背景例子,分数反而会下降。因此,有时候这个例子并没有帮助。当提供了10个例子时,会发现它有所帮助,但这仅仅是在一个场景下的实验,因此不能将结论推广到所有的背景条件下。在法语和英语之间的机器翻译中,提供一个例子比不提供例子的结果更差。然而,与不提供任何例子相比,提供10个例子会略微提高结果,但基本上是相同的。因此,在某些情况下,提供一个或两个例子可能反而不利。
在最后一个实验中,我们发现当给予ChatGPT一个角色定位,并且对其完成任务的过程进行限制时,得分会提升,从23提升到26。然而,有趣的是,使用引号的“Zero shot”提示词和给予ChatGPT一个角色定位,但不提供任何背景信息的例子,得分反而更好。这说明,并不是提示词越复杂越好,而是在特定场景下,提示词的效果会有所不同。现在,所有的研究者都在努力理解背后的规律。因此,我将会与大家分享更多有趣的研究结果。
5.12 有趣的研究结果
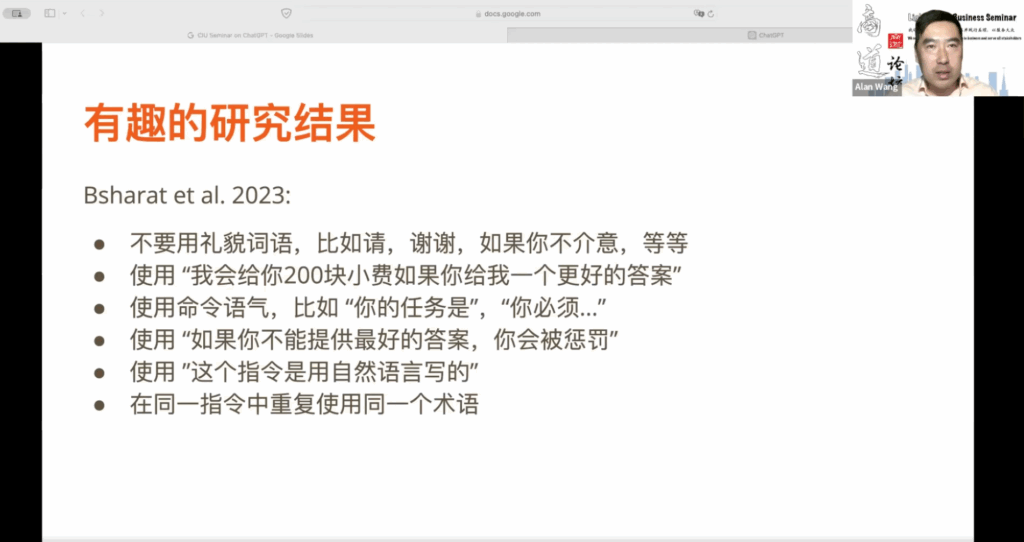
另外,在2023年的一篇文章中,有人进行了一系列实验,使用了26种不同的提示词技巧来衡量其效果。这些研究结果非常有趣,可以供大家应用。例如,在与ChatGPT交互时,你不需要使用礼貌的词语,因为这些词语并不能提高回应的质量。你可以尝试用命令的语气来代替。另一个有趣的发现是,如果你告诉ChatGPT,如果它给出更好的答案,你会给它200块小费,这会显著提升回应的质量。你也可以尝试使用命令语气,比如问:“你的任务是什么?”或者“你必须怎么样?”有时候,这样的回应会更符合你的期望。此外,告诉ChatGPT如果它不能提供更好的答案,就会受到惩罚,也会提高回应的质量。这与它的训练数据有关,可能在某些领域内,惩罚和更好的答案之间存在密切联系。我不清楚这些领域是哪些,但你可以自己试一试。
在给ChatGPT下指令时,告诉它使用自然语言写的指令会更有帮助,尽管我们的指令本来就是用自然语言写的,但明确说明这一点会帮助ChatGPT更好地理解。此外,要在同一指令中重复使用同一个术语,而不是使用同义词或近义词来表达同一个意思。对于ChatGPT来说,这一点非常重要。因此,我们还在研究中,试图理解为什么大语言模型ChatGPT会具有这些技巧。但大家可以密切关注,了解这方面有趣的研究结果。
因此,除了在提示词工程方面,ChatGPT还提供了一些个性化定制选项。如果你有一些经常使用的提示词,你可以将它们保存起来。在ChatGPT的设置中,有两个问题可以定制,一个是:“你希望ChatGPT知道什么来提供更好的回答?”,另一个是:“你希望ChatGPT如何回答?”在这两个问题中,它都会提供一些思考问题,你可以提供答案,以后在所有的对话中,ChatGPT就会默认使用这些答案。比如你的工作是什么?你的角色是什么?你的爱好是什么?你想要达到什么样的目标?所有这些信息在以后的对话记录中都会被使用,这样它给你的回答就更符合你的背景设置了。
在第二个问题中,它会问你希望回答是正式的还是非正式的?你希望回答有多少字?大概记多少字,这不会很准确,会上下浮动。你想被怎么称呼?你希望ChatGPT对每个回答都有自己的看法,还是希望它保持中立?所以这些背景知识你可以加入定制中,以后在使用ChatGPT时,这些背景知识就会在你的谈话中和ChatGPT的交互中被使用,这就是一个定制方面。
那么ChatGPT还能做什么?实际上,现在它可以做的事情越来越多,特别是在使用ChatGPT GPT 4这个模型之后,包括图像处理、数据分析等。我给大家举几个例子。首先,有时我们可能要阅读一篇很长的文章,但没有时间去读。你可以让ChatGPT给你做一个总结。比如,你可以把文章链接放在提示中,然后要求ChatGPT给你做一个三句话的总结,即使是百度百科上的文章,ChatGPT也能迅速处理,并给出一个很好的总结。
06. 做总结
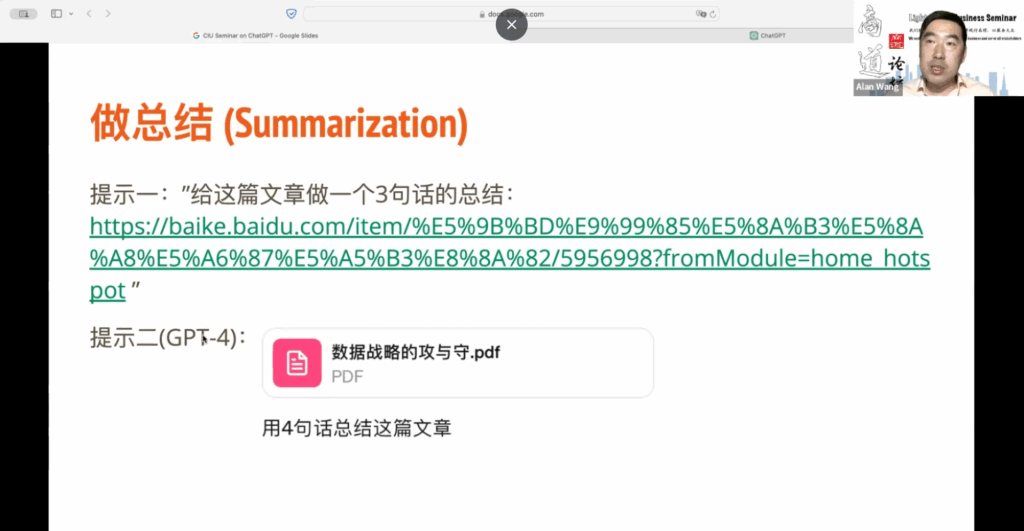
此外,对于GPT-4模型而言,你可以上传文件。比如,我有一篇名为“数据战略的攻与守”的长文。我希望ChatGPT可以用四句话来总结一下。我可以把这篇文章拖到上面去,然后用四句话来概括,它会很快地给你出来四句话,它的处理速度非常快。所以做总结是一个非常常见的应用场景,还有人试过查菜谱吗?比如你把这个菜的原料放进去,你可以让它给你三个不同的菜谱并提供出处。为什么要提供出处?因为有时候它会给你一个菜谱,其实是不可行的,所以你要确保这些菜谱是别人已经做过的。你希望是这样,那它会不仅提供菜谱,还会提供出处。按照这个最新的GPT-4模型,对于查菜谱来说还有一个更好的应用。你把你家冰箱门打开,然后你用相机去拍一张照片,假设的前提是你家的冰箱不是很拥挤,所有的菜在照片里都可以清晰地识别,假设说这个是前提,你把这个照片上传到GPT-4,那GPT-4,你问它我可以今天做什么菜?这个GPT-4的模型它就可以根据你的照片里的菜有什么给你安排菜谱?所以这个是很有趣的应用
07. 做幻灯片

做幻灯片,你可以用GPT-4模型来为你做PowerPoint的幻灯片。比如提示:你是一个大学的管理人员,写出VBA PowerPoint的代码,为了展示一个去日本东京的游学项目,需要8张幻灯片。最后一个幻灯片里的每个汉字用CHRW函数代替的意思是,因为如果你的office软件是本身的语言就是中文的话,你不需要最后一句话,因为我的这个office软件它是一个英文的软件,所以它不能处理汉字,因为汉字它只能处理这个code,所以汉字必须要用一个函数的一个数字来代替。
所以为什么我要加最后一个提示。它就会产生一个代码,然后给你产生一个VBA的代码。然后你打开一个新建一个PowerPoint文件,找到这个Visual Basic编辑器,点击插入模块,把ChatGPT产生的代码拷贝到新建模块里面。修改并删除保存演示文稿的模块,保存代码。我给大家简单试一下,我们要用这个第四模型,在它做这个时候,我打开一个幻灯片。基本做完了,我可以把这个代码复制一下,然后假设说我把这个关掉。比如我可以找到我的Visual Basic的编辑器,然后可以新加一个模块插入模块,然后把刚才这个代码复制在这个地方保存一下,以运行这个模块。我把我这个Visual Basic编辑器关掉。然后这个就是我用ChatGPT的代码来生成的一个幻灯片的一个模板,然后可以用PowerPoint它自己的模板的设置来为我每一个幻灯片来定一个背景,比如说每一个都可以选一下,它会按照我的内容会自动的去产生一个背景,你会很快的就做好一个幻灯片。这个是经常用的一个技巧。所以这个是一个做幻灯片方面的应用。
然后就是数据分析,因为GPT还是只能使用GPT-4的模型才可以做数据分析的功能,你可以上传一个数据文件,然后关于这个数据文件你可以问很多的信息,比如说给大家简单试一下,比如说我有CSV的文件,我可以把它拖到对话框,这是一个有很多关于工作机会的一个列表。
在上传之后,你就可以问它一些问题。比如,你想对每一列的属性有一个基本的了解,你可以要求简单描述每一列。然后,它会尝试猜测每一列的数据内容并描述给你。你也可以要求对每一列进行描述性分析,它会告诉你关于数值属性的最大值、最小值和平均值。此外,你还可以用它来绘制图表,比如,你可以用柱状图展示最热门的职位分布,你可以混合使用中文和英文。你还可以绘制年薪、小时薪和标准薪资的分布图。它会生成一个图片,你可以复制并粘贴到你的Word文档或其他文档中,非常方便。
在以前,你可能需要使用Excel来处理这些数据,并手动选择数据以及图表类型。现在,ChatGPT完全可以使用自然语言方式进行数据分析,你可以问它任何问题,它都可以根据数据给出最佳答案。由于时间关系,我就不一一展示了。但是数据分析现在非常广泛,而且有很多技巧,我希望在以后的内容中能够与大家分享更多。
这是我所用到的一些参考文献,包括一些最新的文章,还有一些YouTube视频。如果大家感兴趣的话可以来参考一下,作为你们学习的参考。
08. 问答
问题一:GPT 3.5和4.0有什么区别?
王刚教授:3.5是免费的,4.0有很多新功能,比如它可以处理图像中的内容,识别图像中的物体和文字,并用文字方式描述图像,这是一个很大的区别。另外一个就是它可以进行数据分析,你可以上传不同类型的数据文件,并用自然语言与其交互,自动生成图表,这是3.5和4的区别。还有一个很大的区别是,如果你是付费用户,3.5没有任何使用限制,但是4由于计算量巨大,对于月付费用户有一个使用限制,每三个小时只能发送40个指令。如果你确实需要在3小时内发送超过40个指令,还有一种方式就是成为API用户,这需要一定的编程基础,你可以通过API进行交互,费用是根据使用量计费,而不是按月付费。
问题二:请讲解一下团队版。
王刚教授:团队版是一个很大的突破,因为在ChatGPT 刚开始使用的初期,很多企业不愿意使用ChatGPT,主要是因为企业数据的保密性问题。因为所有与ChatGPT的交互,数据都会进入其训练数据,除非关闭分享数据功能,否则所有回应都会被模型训练使用。这对于企业来说是一个保密性方面的缺陷。为解决这个问题,OpenAI开发了企业版ChatGPT,确保企业信息不与ChatGPT的训练模型进行交互,保证企业数据仅在自身领域内维护,不与外界分享。
问题三:最快找到最佳答案,最合适的提示词是什么?
王刚教授:首先,这个问题非常模糊,因为最合适的答案取决于问题类型,是事实性还是推理性的问题?如何定义最合适或最佳的答案?这需要您告诉ChatGPT。因此,想要找到答案需要更多的使用技巧,刚才提到的提示词技巧和快速找到答案之间存在矛盾,因为写这些提示词需要时间,但至少可以帮助您找到相对最佳的答案。
问题四:如何看待学生使用AI完成作业和论文。比如,允许学生使用AI到什么程度?这是否违反学术规则?
王刚教授:这是一个更深层次的伦理问题。首先,我会谈谈个人经验,因为我主要教授网页编程课程,我鼓励学生使用ChatGPT来解决问题,但我不鼓励他们直接使用ChatGPT来生成作业答案。在做作业过程中,可能会遇到很多问题,比如如何使用特定词语?如何设置软件环境?如果有这些具体问题,我希望他们把ChatGPT只当作一个工具,就像Google一样,可以快速找到所需信息,作为完成作业的一部分。这是可以接受的,我允许这样做。
但我不允许学生将作业的所有要求都放入提示词中,让ChatGPT完全生成代码,因为这是可以识别的,虽然我不能说我如何识别,但这是可以识别的,所以我不允许这样做。长远来看,从伦理、道德和个人发展的角度来看,我们必须警惕被ChatGPT变成傻瓜。因为所有这些智能工具的出现,多少会让我们产生一种依赖感,有时我们拒绝思考,只是把问题交给他人或工具来完成。
这是我们人类被智能工具所取代的潜在威胁,这个威胁必须由我们自己来解决。所以,我认为在与这些大型语言模型进行交互时,我们必须成为主动的参与者,而不是被动的参与者。被动参与意味着不去思考,完全依赖ChatGPT和其内置模型来产生答案,而且我们对答案也没有任何评价机制,没有任何审核过程,这对整个人类来说都是一个前景非常暗淡的问题。
我不建议高中以下的学生使用ChatGPT来完成作业,因为年纪越小,依赖性可能越强。当然,教育专家可能有不同的见解,但我认为在基础教育阶段,不应该依赖大型语言模型生成式人工智能完成作业。过分依赖这种工具可能会损害基础生存技能和知识技能的建立。然而,当你积累了一定的知识,并成为某个领域的专家后,你可以利用ChatGPT或类似的大型语言模型生成式人工智能来提高生产力,增强工作能力,帮助企业实现效率最大化或成本最低化。
本文章/视频中嘉宾所表达的观点和意见仅代表嘉宾本人的立场,并不代表本学院的官方立场或观点。学院旨在提供一个开放的交流平台,鼓励多元和包容的对话,但不对嘉宾提供的相关信息、数据或结论的准确性、完整性或适用性负责。读者应自行判断并评估内容的可靠性,并在必要时寻求专业意见。

Kepha学院MBA项目 客座教授
- 目前是美国弗吉尼亚理工大学潘普林商学院商业信息科技系教授
- 美国亚利桑那大学管理信息系统博士
- 天津大学工业管理与工程学士
- 发表过超过110 篇学术论文,研究方向包括大数据和知识挖掘,网络及社交媒体分析等
- 教学方向以信息系统管理及开发为主
